Logging in Python multiprocessing applications presents unique challenges that can trip up even experienced developers. You might find your logs jumbled, incomplete, or worse—corrupted. How do you ensure your logs remain accurate and useful when your code runs across multiple processes? This guide will walk you through the complexities of logging in Python multiprocessing environments, from basic setup to advanced techniques.
Understanding the Challenges of Logging in Multiprocessing
Logging in a multiprocessing environment is not as straightforward as in single-process applications. The main challenges stem from the concurrent nature of multiprocessing, which can introduce several complications in maintaining accurate and reliable logs. Some key challenges are:
- Race Conditions: Multiple processes might try to write to the same log file simultaneously, leading to corrupted or incomplete log entries. If two processes log a message simultaneously, the output may contain jumbled text that is difficult to interpret.
- File Access Issues: When multiple processes attempt to open and write to the same file, you may encounter file-locking problems or unexpected behavior. Operating systems typically allow only one process to write to a file simultaneously. If another process tries to access the file while it is locked, it may fail to write or block until the lock is released, leading to performance bottlenecks.
- Message Overlap: Log messages from different processes can interleave, making it difficult to trace the execution flow. For instance, if two processes log messages simultaneously, the output may appear as a single, confusing stream of logs. This overlap can make debugging difficult, as it becomes hard to determine which message originated from which process.
- Data Corruption: Log data can become corrupted or partially written without proper synchronization. This can happen if a process crashes while writing to the log file, leaving behind incomplete entries. Such corruption can hinder the ability to analyze logs effectively, especially in critical applications where logs are used for auditing or troubleshooting.
To address these issues, you need thread-safe logging mechanisms. Thread-safe logging ensures that log messages are written atomically, preventing interleaving or corruption of log data. This is typically achieved by using synchronization primitives, such as locks or semaphores, to control access to the log file or logging resources. By acquiring a lock before writing to the log and releasing it afterwards, multiple processes can safely share the logging infrastructure without interfering with each other's log entries.
Quick Guide: Setting Up Basic Multiprocessing Logging
Let's start with a simple setup for multiprocessing logging:
Case 1: Sequential Multi-process Logging
import multiprocessing
import logging
import time
def worker_process(name):
logger = multiprocessing.get_logger()
start_time = time.time()
logger.info(f"Worker {name} started at {start_time}")
# Simulate some work
time.sleep(2)
end_time = time.time()
logger.info(f"Worker {name} finished at {end_time} (Duration: {end_time - start_time:.2f} seconds)")
if __name__ == "__main__":
# Set up logging for the main process
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(processName)s - %(levelname)s - %(message)s')]
# Set up multiprocessing logging
multiprocessing.log_to_stderr(logging.INFO)
processes = []
for i in range(3):
p = multiprocessing.Process(target=worker_process, args=(f"Worker-{i}",))
processes.append(p)
p.start()
for p in processes:
p.join()
print("All processes have completed.")
Output:
[INFO/Process-1] Worker Worker-0 started at 1724832061.0959587
All processes have completed.
[INFO/Process-2] child process calling self.run()
[INFO/Process-2] Worker Worker-1 started at 1724832061.0975811
All processes have completed.
[INFO/Process-3] child process calling self.run()
[INFO/Process-3] Worker Worker-2 started at 1724832061.1468613
[INFO/Process-1] Worker Worker-0 finished at 1724832063.0984426 (Duration: 2.00 seconds)
[INFO/Process-1] process shutting down
[INFO/Process-1] process exiting with exitcode 0
[INFO/Process-2] Worker Worker-1 finished at 1724832063.1049902 (Duration: 2.01 seconds)
[INFO/Process-2] process shutting down
[INFO/Process-2] process exiting with exitcode 0
[INFO/Process-3] Worker Worker-2 finished at 1724832063.1495423 (Duration: 2.00 seconds)
[INFO/Process-3] process shutting down
[INFO/Process-3] process exiting with exitcode 0
All processes have completed.
[INFO/MainProcess] process shutting down
Case 2: Parallel Multi-Process Logging
import multiprocessing
import logging
import time
def worker_process(name):
logger = multiprocessing.get_logger()
start_time = time.time()
logger.info(f"Worker {name} started at {start_time}")
# Simulate some work
time.sleep(2)
end_time = time.time()
logger.info(f"Worker {name} finished at {end_time} (Duration: {end_time - start_time:.2f} seconds)")
if __name__ == "__main__":
# Set up logging for the main process
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(processName)s - %(levelname)s - %(message)s')
# Set up multiprocessing logging
multiprocessing.log_to_stderr(logging.INFO)
processes = []
for i in range(3):
p = multiprocessing.Process(target=worker_process, args=(f"Worker-{i}",))
processes.append(p)
p.start() # Start process in parallel
for p in processes:
p.join() # Wait for all processes to complete
print("All processes have completed.")
Output:
[INFO/Process-2] child process calling self.run()
[INFO/Process-2] Worker Worker-1 started at 1724831271.836578
[INFO/Process-1] child process calling self.run()
[INFO/Process-1] Worker Worker-0 started at 1724831271.8374515
[INFO/Process-3] child process calling self.run()
[INFO/Process-3] Worker Worker-2 started at 1724831271.8470223
[INFO/Process-2] Worker Worker-1 finished at 1724831273.8374174 (Duration: 2.00 seconds)
[INFO/Process-2] process shutting down
[INFO/Process-2] process exiting with exitcode 0
[INFO/Process-1] Worker Worker-0 finished at 1724831273.841227 (Duration: 2.00 seconds)
[INFO/Process-1] process shutting down
[INFO/Process-1] process exiting with exitcode 0
[INFO/Process-3] Worker Worker-2 finished at 1724831273.8884654 (Duration: 2.04 seconds)
[INFO/Process-3] process shutting down
[INFO/Process-3] process exiting with exitcode 0
All processes have completed.
[INFO/MainProcess] process shutting down
In both the cases, the worker_process function logs the start and finish times along with the duration of each process. For sequential execution, processes are started one by one and completed before the next starts, ensuring no overlap, while in parallel execution, processes start concurrently, showing overlapping log timestamps. Logging is configured using logging.basicConfig and multiprocessing.log_to_stderr to handle output from multiple processes. Sequential execution waits for each process to finish using p.join(), while parallel execution allows all processes to run simultaneously, with logs indicating their concurrent operation. This approach leverages the built-in capabilities of the multiprocessing module to ensure that logging is handled correctly across multiple processes.
Best Practices for Basic Multiprocessing Logging:
- Use
multiprocessing.get_logger()in child processes to ensure thread-safety. This function provides a logger that is specifically designed for use in multiprocessing contexts, ensuring that log messages are handled safely and correctly. - Set appropriate log levels (e.g.,
DEBUG,INFO,WARNING,ERROR) to control the verbosity of your logs. This helps filter out unnecessary information and makes it easier to focus on important messages. - Initialize loggers in child processes to avoid inheriting parent process configurations. This ensures that each process has its own logging context, which can help prevent unintended log messages from being mixed.
- When multiple processes log to the same file, improper handling can lead to conflicts and overlapping entries. Log rotation can help mitigate this by ensuring that each process has its own log file during rotation periods, thereby reducing the chances of log entries being mixed or corrupted.
Deep Dive: Advanced Logging Techniques for Multiprocessing
A queue-based logging system makes things run smoother, especially in more complex scenarios. Unlike the direct logging approach, we just read about in the previous section, where each process logs its messages independently. This can lead to logging conflicts and inefficiencies, the queue-based method centralizes everything.
Each worker process sends its log messages to a shared queue. Then, a dedicated logging thread or process takes care of pulling messages from the queue and writing them out. This setup avoids the chaos of multiple processes trying to log at the same time and improves efficiency by separating the generation of logs from their actual writing. In contrast to the multi-threading approach, where log writing can still cause problems if multiple threads are logging simultaneously, the queue-based system ensures orderly and efficient log handling by managing all logs through a single channel.
Here's how to implement it:
import multiprocessing
import logging
import logging.handlers
import queue
# Function to set up a logger with a QueueHandler
def setup_logger():
logger = logging.getLogger("multiprocessing_logger")
logger.setLevel(logging.INFO)
# QueueHandler to send log records to a logging queue
queue_handler = logging.handlers.QueueHandler(multiprocessing.Queue(-1))
logger.addHandler(queue_handler)
return logger
# Function that will be executed by each worker process
def worker_process(name):
logger = setup_logger()
logger.info(f"Worker {name} is starting")
# Your worker process code here
logger.info(f"Worker {name} is finished")
# Function that runs in the logger process, handling log records from the queue
def logger_process(queue):
root = logging.getLogger()
handler = logging.StreamHandler()
# Add a handler to output logs to the console
root.addHandler(handler)
root.setLevel(logging.INFO)
while True:
try:
# Get log record from the queue
record = queue.get()
# Check for the termination signal (None)
if record is None:
break
# Get the logger specified by the record and process the log message
logger = logging.getLogger(record.name)
logger.handle(record)
except Exception:
import sys, traceback
print('Error in logger process', file=sys.stderr)
traceback.print_exc(file=sys.stderr)
if __name__ == "__main__":
# Create a multiprocessing queue for log records
log_queue = multiprocessing.Queue(-1)
# Start the logger process that will handle all logs
logger_p = multiprocessing.Process(target=logger_process, args=(log_queue,))
logger_p.start()
# List to keep track of worker processes
processes = []
for i in range(5):
# Start a new worker process
p = multiprocessing.Process(target=worker_process, args=(f"Worker-{i}",))
processes.append(p)
p.start()
# Wait for all worker processes to complete
for p in processes:
p.join()
# Signal the logger process to exit
log_queue.put_nowait(None)
# Wait for the logger process to finish
logger_p.join()
This setup uses a QueueHandler to send log records to a separate logging process. The logging process receives records from the queue and writes them to the desired output.
Configuring Formatters and Handlers for Multiprocessing Logs
To make your logs more informative and easier to parse, you can customize formatters and handlers:
import logging
import multiprocessing
class ProcessNameFilter(logging.Filter):
def filter(self, record):
record.processName = multiprocessing.current_process().name
return True
# formatter for log messages
formatter = logging.Formatter('%(asctime)s - %(processName)s - %(levelname)s - %(message)s')
handler = logging.StreamHandler()
handler.setFormatter(formatter)
# Add the custom filter to the handler
handler.addFilter(ProcessNameFilter())
# logger for multiprocessing
logger = logging.getLogger("multiprocessing_logger")
logger.addHandler(handler)
logger.setLevel(logging.INFO)
This configuration adds the process name to each log message, making it easier to trace which process generated each log entry.
Tips for Organizing Multiprocessing Logs:
- Use unique identifiers for each process in log messages.
- Consider using different log files for different types of processes, which helps prevent performance degradation and data loss. You can implement as:
logging.FileHandler(f"{process_type}_{datetime.now().strftime('%Y%m%d')}.log") - Implement log rotation to manage log file sizes in long-running applications, which helps prevent performance degradation and data loss.
- Utilize a centralized logging system to aggregate logs from multiple processes, making it easier to analyze and monitor application behavior.
Troubleshooting Common Multiprocessing Logging Issues
When working with multiprocessing logging, you might encounter several common issues:
Log Message Overlap: Use a queue-based logging system to centralize log writing and prevent overlap.
Missing Log Entries: Ensure that all processes are properly closing their log handlers before exiting.
try: # Your processing logic finally: logger.handlers.clear() # Close and flush handlersPerformance Bottlenecks: If logging slows down your application, consider using asynchronous logging or reducing log verbosity.
# Asynchronous logging queue_handler = QueueHandler(log_queue) logger.addHandler(queue_handler) # Reducing verbosity logger.setLevel(logging.WARNING) # Adjust level to reduce logging overheadLogging Failures in Child Processes: Implement error handling in your logging code to catch and report any logging-related exceptions.
try: logger.info("Processing data") except Exception as e: logger.error(f"Logging failed: {e}")
To debug logging issues:
Temporarily increase log verbosity to capture more details. This helps in diagnosing issues by providing more context around the operations leading to the problem. In production, it's best to configure your logging system to exclude debug logs as it can lead to several problems such as performance overhead, security risks and increase log storage. To exclude debug logs set the log level to
INFOor higher.logger.setLevel(logging.DEBUG)Use process and thread IDs in log messages to trace the source of problematic logs. This is especially useful when logs from multiple processes are being handled by a centralized logger, as it allows you to trace back the source of problematic logs.
formatter = logging.Formatter('%(asctime)s - %(process)d - %(thread)d - %(message)s') handler.setFormatter(formatter)Implement a try-except block around logging calls to catch and report any logging exceptions. This can help prevent your application from crashing due to logging failures and ensures that you are aware of any issues that might be affecting log generation.
try: logger.debug("Debugging message") except Exception as e: print(f"Logging error: {e}")Monitor Resource Usage during logging. Excessive logging can lead to increased CPU and memory usage, which might impact the performance of your application.
import psutil memory_usage = psutil.Process().memory_info().rss cpu_usage = psutil.cpu_percent() logger.debug(f"Memory usage: {memory_usage}, CPU usage: {cpu_usage}%")Test in Isolated Environments by running minimal processes for easier debugging. This can make it easier to replicate and identify issues without the noise of a fully operational system.
# For Example: To run only 2 processes for isolated testing for i in range(2): p = multiprocessing.Process(target=your_function) p.start()
Optimizing Logging Performance in Multiprocessing Applications
Logging can significantly impact the performance of your multiprocessing application. Here are some strategies to optimize logging performance:
Use Asynchronous Logging: Implement a separate logging process to handle log writing asynchronously. This decouples logging from your main processing tasks, reducing the impact on performance. Let’s take an example:
import logging import concurrent.futures import time import queue # Create a logger logger = logging.getLogger('AsyncLogger') logger.setLevel(logging.DEBUG) formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # Console handler for the logger console_handler = logging.StreamHandler() console_handler.setFormatter(formatter) logger.addHandler(console_handler) # Queue to hold log messages log_queue = queue.Queue() # Thread function to write log messages from the queue def log_writer(): while True: message = log_queue.get() if message is None: # Sentinel value to shut down the thread break logger.log(message['level'], message['msg']) # Function to add a log message to the queue def async_log(level, msg): log_queue.put({'level': level, 'msg': msg}) # Start the log writer thread with concurrent.futures.ThreadPoolExecutor(max_workers=1) as executor: future = executor.submit(log_writer) # Main application code for i in range(5): async_log(logging.INFO, f'Log message {i}') time.sleep(0.1) # Simulate some work # Shutdown the log writer log_queue.put(None) # Send shutdown signal future.result() # Wait for the log writer thread to finishOutput:
2024-08-28 12:40:46,762 - AsyncLogger - INFO - Log message 0 2024-08-28 12:40:46,862 - AsyncLogger - INFO - Log message 1 2024-08-28 12:40:46,963 - AsyncLogger - INFO - Log message 2 2024-08-28 12:40:47,064 - AsyncLogger - INFO - Log message 3 2024-08-28 12:40:47,165 - AsyncLogger - INFO - Log message 4This example uses Python's
concurrent.futuresand queue for efficient asynchronous logging. Theasync_logfunction adds messages to a queue, acting as a buffer between main tasks and logging. A separate thread, managed byThreadPoolExecutor, runs thelog_writerfunction, which continuously processes messages from the queue and writes them using the logger. The future object ensures that all log messages are processed before the application exits, withfuture.result()used to wait for the logging thread to complete after receiving a shutdown signal(None). This setup keeps the main loop unblocked by logging operations, ensuring smooth application performance.Batch Log Messages: Instead of writing each log message immediately, batch multiple messages and write them together. It reduces the number of I/O operations by writing multiple log messages at once instead of individually.
Implement Log Levels: Use appropriate log levels to control the amount of information logged in production environments. This helps to minimize the performance impact of logging by avoiding unnecessary log entries.
Use Memory Handlers: For high-throughput scenarios, consider using
MemoryHandlerto buffer log records in memory before flushing to disk. This can significantly reduce the frequency of I/O operations, improving performance.
import logging
from logging.handlers import MemoryHandler, RotatingFileHandler
# Create a RotatingFileHandler
file_handler = RotatingFileHandler("app.log", maxBytes=1024*1024, backupCount=3)
# Create a MemoryHandler that flushes to the file handler
memory_handler = MemoryHandler(capacity=1000, flushLevel=logging.ERROR, target=file_handler)
logger = logging.getLogger("high_performance_logger")
logger.addHandler(memory_handler)
logger.setLevel(logging.INFO)
This setup buffers log messages in memory and only writes to disk when the buffer is full or when an error-level message is logged, significantly reducing I/O operations.
Leveraging SigNoz for Advanced Multiprocessing Logging and Monitoring
While the techniques discussed so far provide solid foundations for multiprocessing logging, complex applications often require more advanced solutions. SigNoz offers a comprehensive logging and monitoring solution that can significantly enhance your multiprocessing logging capabilities.
SigNoz cloud is the easiest way to run SigNoz. Sign up for a free account and get 30 days of unlimited access to all features.

You can also install and self-host SigNoz yourself since it is open-source. With 19,000+ GitHub stars, open-source SigNoz is loved by developers. Find the instructions to self-host SigNoz.
SigNoz provides several key benefits for multiprocessing applications:
- Centralized Log Management: SigNoz can aggregate logs from all your processes into a single, searchable interface, eliminating the need to manually aggregate logs from multiple sources. This centralized approach simplifies log management and enables efficient log analysis across distributed systems.
- Real-time Log Analysis: With SigNoz, you can analyze your logs in real-time, making it easier to detect and respond to issues quickly. This capability allows you to gain immediate insights into your application’s behavior and address problems before they escalate.
- Correlation with Metrics and Traces: SigNoz allows you to correlate your logs with metrics and traces, providing a holistic view of your application's performance. By linking logs with specific metrics and tracing spans, you can better understand the context of issues and pinpoint the exact causes of performance bottlenecks or errors.
- Custom Dashboards: Create custom dashboards to visualize log data from your multiprocessing application, making it easier to spot trends and anomalies.
Logging with OpenTelemetry and SigNoz in Python Flask Applications
Prerequisites
- Python 3.7+
- Flask
- OpenTelemetry libraries
- SigNoz account and ingestion key
Installation
Install the required packages:
pip install flask opentelemetry-api opentelemetry-sdk opentelemetry-exporter-otlp
Sample Flask App
Setup a sample flask app that sends the logs to SigNoz using OpenTelemetry
import multiprocessing
import logging
import time
import random
from flask import Flask
from opentelemetry import trace
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
# Configure OpenTelemetry
resource = Resource(attributes={"service.name": "multiprocessing-app"})
# Trace configuration
trace.set_tracer_provider(TracerProvider(resource=resource))
otlp_span_exporter = OTLPSpanExporter()
span_processor = BatchSpanProcessor(otlp_span_exporter)
trace.get_tracer_provider().add_span_processor(span_processor)
# Log configuration
logger_provider = LoggerProvider(resource=resource)
otlp_log_exporter = OTLPLogExporter()
logger_provider.add_log_record_processor(BatchLogRecordProcessor(otlp_log_exporter))
otel_handler = LoggingHandler(level=logging.INFO, logger_provider=logger_provider)
# Configure root logger
root_logger = logging.getLogger()
root_logger.setLevel(logging.INFO)
root_logger.addHandler(otel_handler)
# Add console handler
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_formatter = logging.Formatter('%(asctime)s - %(processName)s - %(levelname)s - %(message)s')
console_handler.setFormatter(console_formatter)
root_logger.addHandler(console_handler)
app = Flask(__name__)
def worker_process(worker_id):
logger = logging.getLogger(f"Worker-{worker_id}")
logger.info(f"Worker {worker_id} started")
for _ in range(5):
time.sleep(random.uniform(0.5, 2))
logger.info(f"Worker {worker_id} is processing")
logger.info(f"Worker {worker_id} finished")
@app.route('/')
def trigger_workers():
logging.info("Triggering worker processes")
processes = []
for i in range(3):
p = multiprocessing.Process(target=worker_process, args=(i,))
processes.append(p)
p.start()
for p in processes:
p.join()
return "Workers completed their tasks. Check the logs!"
if __name__ == '__main__':
app.run(host='0.0.0.0', port=9090)
In this implementation, we've set up a robust logging system that works with both simple Flask applications and those using multiprocessing.
- OpenTelemetry Integration: We've integrated OpenTelemetry for both tracing and logging. This allows us to send structured logs and traces to SigNoz, providing a comprehensive view of our application's behavior.
- Dual Logging: We've configured the logger to send logs to both the console and SigNoz. This allows for real-time monitoring during development and centralized log management in production.
- Custom Formatting: We've set up custom log formatters for both console and SigNoz logs, ensuring that we capture relevant information like timestamps, log levels, and process names (crucial for multiprocessing scenarios).
- Multiprocessing Support: In the multiprocessing version, we've ensured that logs from child processes are correctly captured and sent to both the console and SigNoz.
- Flask Integration: We've seamlessly integrated this logging setup with Flask, allowing us to log application events and API calls easily.
- Configurability: The setup allows for easy configuration of log levels and service names, making it adaptable to different environments and requirements.
- SigNoz Compatibility: By using the OTLP exporter, we've ensured that our logs are compatible with SigNoz's ingestion format, allowing for easy visualization and analysis in the SigNoz dashboard.
This implementation provides a comprehensive logging solution that works across different application architectures while providing the benefits of both local and centralized logging. It offers developers immediate feedback via console logs and enables robust log management and analysis through SigNoz integration.
Running the Application
To run your application and send logs to SigNoz, use the following command:
OTEL_PYTHON_LOGGING_AUTO_INSTRUMENTATION_ENABLED=true \\
OTEL_EXPORTER_OTLP_ENDPOINT=https://ingest.{region}.signoz.cloud:443 \\
OTEL_EXPORTER_OTLP_HEADERS=signoz-ingestion-key=<YOUR_INGESTION_KEY> \\
opentelemetry-instrument --traces_exporter otlp --metrics_exporter otlp --logs_exporter otlp python your_app.py
Replace {region} with your SigNoz cloud region (us, in, or eu) and <YOUR_INGESTION_KEY> with your actual SigNoz ingestion key.
Viewing Logs
After running your application and generating some logs:
Check your terminal to see the logs printed to the console.
2. Log in to your SigNoz dashboard to view the logs sent to SigNoz. You should now see your application logs both in the terminal and in the SigNoz dashboard.
You should now see your application logs both in the terminal and in the SigNoz dashboard.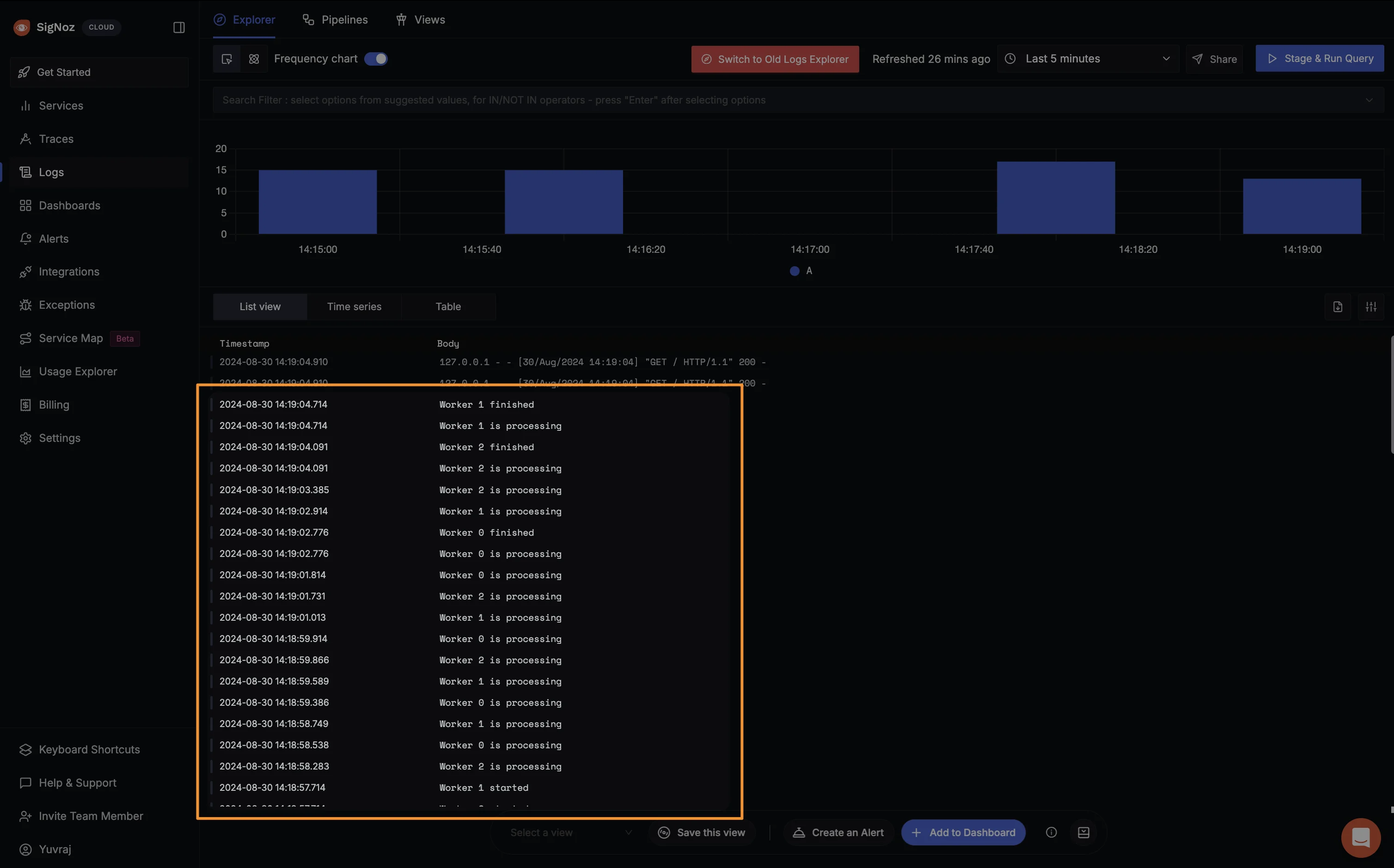
Key Takeaways
- Multiprocessing logging requires special consideration due to concurrency issues.
- Use queue-based logging with a separate logging process for thread-safety and improved performance.
- Properly configure formatters and handlers to organize and enrich your multiprocessing logs.
- Optimize logging performance to minimize impact on your application's efficiency.
- Consider using advanced tools like SigNoz for comprehensive log management in complex multiprocessing applications.
FAQs
How does logging differ between threading and multiprocessing in Python?
Threading and multiprocessing in Python have different implications for logging:
- Threading: Threads share the same memory space, so you can use a single logger instance across all threads. However, you need to ensure thread-safety when logging.
- Multiprocessing: Each process has its own memory space, so you need to create separate logger instances for each process. You also need to handle log file access and potential race conditions.
Can I use the standard logging module with multiprocessing?
Yes, you can use the standard logging module with multiprocessing, but you need to take extra precautions:
- Use
multiprocessing.get_logger()to get a multiprocessing-safe logger. - Configure logging in each child process to avoid inheriting configurations from the parent process.
- Consider using a queue-based logging system to better perform and avoid file access issues.
What are the best practices for logging in a distributed system using Python?
When logging in a distributed system:
- Use a centralized logging system to aggregate logs from all nodes.
- Each log message includes unique identifiers (e.g., node ID, process ID).
- Use structured logging formats like JSON for easier parsing and analysis.
- Implement log levels consistently across all components of your system.
- Consider using distributed tracing alongside logging for better visibility into system behavior.
How can I ensure my logs are not corrupted when using multiprocessing?
To prevent log corruption in multiprocessing:
- Use a queue-based logging system with a separate logging process.
- Implement proper locking mechanisms if multiple processes write to the same file.
- Use atomic operations for log writes when possible.
- Consider using a centralized logging service like SigNoz to handle log aggregation and storage.

