Python performance monitoring is a critical aspect of maintaining efficient and reliable applications. It involves tracking key metrics, identifying bottlenecks, and optimizing code to ensure your Python programs run smoothly.
Imagine launching a new feature that slows down your application or causes crashes. Such issues can frustrate users and harm your reputation. Real-time performance monitoring acts as a safeguard to detect and address problems before they escalate.
In this guide, we will understand Python performance monitoring, discuss popular python performance montioring tools, and how to implement with native python libraries like py-spy and memory_profiler and full-scale APM solutions like SigNoz.
What is Python Performance Monitoring?
Python application monitoring is the practice of keeping an eye on and gathering data regarding your application's performance and health to ensure it will function as intended.
Analogy
Keeping an eye on a Python application is similar to flying an airplane. Just as pilots use instruments to monitor the performance of their aircraft, developers utilize Python monitoring tools to check the health of the applications. In the same way, a pilot checks the dashboard to ensure everything functions well while in flight, and developers can view how the application operates in real-time.
How we achieve this?
This involves using open-source tools for Python performance benchmarking and Python real-time monitoring. These tools give developers access to critical data such as the application's response time, memory usage, and concurrent task count. In addition, they monitor specific actions such as database searches and API calls and search for errors.
Unlike system-level monitoring, which primarily tracks hardware resources, Python performance monitoring delves into the application layer. It provides insights into:
- Function-level performance
- Memory allocation patterns
- Database query efficiency
- API response times
This granular approach allows you to pinpoint specific areas of your code that may be causing performance issues.
Why is Python Performance Monitoring Critical?
In the current software environment, real-time application monitoring is advantageous and essential for the production environment. Python is user-friendly and helps in creating basic web applications as well as advanced AI tools. Because of its dynamic nature, it sometimes experiences unexpected slowdowns. This is where Python Application Performance Monitoring (APM) comes into the picture.
Implementing robust Python performance monitoring is essential for several reasons:
- APM is essential because it enables developers to identify and fix challenging application performance issues to maintain a continuously running application.
- Finding problems is not the goal; rather, proactive optimization is needed to ensure Python applications function properly in various scenarios, such as those involving heavy data processing or traffic.
- With real-time monitoring tools, developers can receive instant feedback on how code modifications impact the performance of their applications, which will help in overall production and enhance user experience.
- This continuous feedback loop can assist in making data-driven decisions that increase performance and are essential for continuous improvement.
- Python Application Performance Monitoring is an essential step in the development process that ensures apps can handle jobs in the real world.
- Performance monitoring is essential to creating software that meets user expectations and system needs, regardless of the program size you are producing, from simple scripts to massive open-source and corporate applications.
Common Performance Issues in Python Applications
Python applications often face several performance challenges:
- Memory Leaks: Unchecked memory usage can lead to slow degradation of application performance over time.
- CPU-Bound Operations: Computationally intensive tasks can block other processes, reducing overall responsiveness.
- I/O Bottlenecks: Inefficient database queries or external API calls can significantly slow down your application.
- Inefficient Algorithms: Poorly optimized code can lead to unnecessary resource consumption and slower execution times.
Top Python Performance Monitoring Tools
Several tools can help you monitor and optimize your Python applications:
Open-source Options: Prometheus, Grafana, and SigNoz offer powerful monitoring capabilities for Python applications.
SigNoz cloud is the easiest way to run SigNoz. Sign up for a free account and get 30 days of unlimited access to all features.

You can also install and self-host SigNoz yourself since it is open-source. With 19,000+ GitHub stars, open-source SigNoz is loved by developers. Find the instructions to self-host SigNoz.
Cloud-native Solutions: AWS CloudWatch and Google Cloud Monitoring provide integrated monitoring for cloud-based Python apps.
Comprehensive APM Platforms: New Relic and Datadog offer extensive monitoring features with Python SDK integration but often comes with hefty billing charges.
Python-specific Libraries: Tools like py-spy and memory_profiler allow for targeted performance analysis.
Key Metrics for Python Performance Monitoring
Understanding the metrics to keep an eye on is essential to maintaining the optimal performance of your Python applications. We can track various performance metrics using SigNoz. It is an open-source application performance monitoring tool that helps you track various performance metrics for your Python applications. Here are examples of how to monitor key metrics using SigNoz, with details on how each metric is derived from span data:
- Response Time is the amount of time it takes for a program to reply to a user's request. Faster responses result in a better user experience. SigNoz tracks response time using latency metrics derived from spans. The
signoz_latency_bucket,signoz_latency_sum, andsignoz_latency_countmetrics help in monitoring response times. You can set up alerts if the latency exceeds a certain threshold, indicating potential performance bottlenecks.
# Example latency bucket metric
signoz_latency_bucket{http_status_code="200", operation="/Address", service_name="shippingservice", span_kind="SPAN_KIND_SERVER", status_code="STATUS_CODE_UNSET", le="100"} 10180
- CPU Usage: The amount of CPU power your application uses. Increased utilization may be a sign of inefficient programming or a hardware upgrade. SigNoz focuses on span data, you can integrate it with other tools like Prometheus to monitor CPU usage. Use metrics from Prometheus to visualize CPU usage on a SigNoz dashboard.
# Example CPU usage metric integrated with Prometheus
process_cpu_seconds_total{job="myapp", instance="instance1"} 12345.67
- Memory Usage: Monitor the RAM your application is using. By monitoring this, memory leaks and other associated problems can be avoided. Similar to CPU usage, memory usage can be monitored using Prometheus and visualized on SigNoz dashboards.
# Example memory usage metric integrated with Prometheus
process_resident_memory_bytes{job="myapp", instance="instance1"} 123456789
- Throughput: Indicates how many tasks or transactions your application can complete in a specific amount of time. Higher throughput rates frequently reflect better performance. SigNoz tracks request counts using the
signoz_calls_totalmetric. You can monitor the number of requests per second and set up alerts if the throughput drops below a certain level.
# Example request count metric
signoz_calls_total{http_status_code="200", operation="/Address", service_name="shippingservice", span_kind="SPAN_KIND_SERVER", status_code="STATUS_CODE_UNSET"} 142
- Error Rates: Record the kind and frequency of errors encountered. Low error rates are essential to ensure stability and reliability. SigNoz computes error counts from the
signoz_calls_totalmetric with an "Error" status code. You can monitor error rates and set up alerts to respond quickly to critical issues.
# Example error count metric
signoz_calls_total{http_status_code="503", operation="/checkout", service_name="frontend", span_kind="SPAN_KIND_CLIENT", status_code="STATUS_CODE_ERROR"} 220
- Database Performance: This section contains query timings and errors in the database. Achieving the best possible application performance requires effective database interactions. As, SigNoz tracks database latency using
signoz_db_latency_sumandsignoz_db_latency_countmetrics. You can monitor database performance and optimize slow queries based on these metrics.
# Example database latency metric
signoz_db_latency_sum{operation="/dbQuery", service_name="databaseservice", span_kind="SPAN_KIND_SERVER", status_code="STATUS_CODE_UNSET"} 1000
signoz_db_latency_count{operation="/dbQuery", service_name="databaseservice", span_kind="SPAN_KIND_SERVER", status_code="STATUS_CODE_UNSET"} 50
Monitoring Python Application Performance with Monitoring Tool
Using Python application monitoring tools is similar to having an advanced health check system. To do this, we can use observability tool like SigNoz. SigNoz helps identify areas requiring development by giving developers real-time data on how well your application is doing. It is an OpenTelemetry-based, robust, and easily navigable open-source observability tool alternative to DataDog and New Relic.
Python application monitoring is made more accessible with SigNoz, as it provides a uniform platform for visualizing application traces and data. Full-fledged distributed tracing is supported, which aids in identifying the underlying reasons for failures or performance bottlenecks in a microservices architecture.
These tools can integrate seamlessly to give a comprehensive view of your application's performance, helping developers make data-driven decisions.
Benefits of Monitoring Python Applications
Monitoring Python Applications has several advantages:
- Proactive Issue Resolution: Spot and fix problems before they affect users.
- Enhanced Performance: Constant observation enables performance optimization, resulting in quicker and more dependable applications.
- Better Resource Management: Increased cost savings may result from better understanding and using your computational resources.
- Enhanced User Satisfaction: User retention and satisfaction are raised by an application that runs smoothly.
- Data-Driven Decisions: Utilizing performance data facilitates well-informed decisions on scalability and upgrades.
Monitoring involves more than just addressing problems; it also involves aiming for optimal application performance and dependability.
Monitoring Python Application with SigNoz
Step 1: Setup SigNoz
SigNoz cloud is the easiest way to run SigNoz. Sign up for a free account for 30 days of unlimited access to all features.
Or you can also install and self-host SigNoz yourself since it is open-source. Find the instructions to self-host SigNoz.
Step 2: Building a Python Sample Application
We can build any Python application to monitor. This could be a basic API using Flask or any advanced application
In this guide, we are using a flask-based application.
Prerequisites:
- Having Git installed in your system
- Docker Installed to interact with MongoDB
Clone sample Flask app repository
From your terminal use the following command to clone a sample Flask app GitHub repository.
git clone https://github.com/SigNoz/sample-flask-app.git
cd sample_flask-app
Create a virtual environment and activate it
Go inside the directory sample_flask_app and create a virtual environment there using the below commands:
python3 -m venv .venv
source .venv/bin/activate
Install dependencies to run the app:
After you cloned the repo, you have seen the requirements.txt file to install the dependencies we need to run this particular application.
pip install -r requirements.txt
Run your flask based Application
python3 app.py
This application is running on http://localhost:5002
But we haven’t installed instrumentation packages yet. We will do this in the next step make sure to stop your application and kill the process as well.
To find out which process is using port 5002, use the lsof command with the -i flag:
sudo lsof -i :5002
lsof: Lists open files and network connections.i :5002: Filters the results to show only processes using port5002.
As we are running the Flask app on http://localhost:5002, this command helps you check if another process is already using this port. If you see that http://localhost:5002 is occupied, killing the process releases the port so you can run your application on it. Identify the Process ID (PID) from the lsof output, you need to stop this process to free up the port using sudo kill -9 <process-id>
Ensuring http://localhost:5002 is available is crucial before starting your application or installing new monitoring tools. This avoids conflicts and ensures smooth operation.
Step 3: Instrumentation with OpenTelemetry and sending data to SigNoz
In your Python Flask application, Install the instrumentation packages using this command :
opentelemetry-bootstrap --action=install
After installing the open telemetry package, you just need to configure a few environment variables for your OTLP exporters. Environment variables that need to be configured:
service.nameapplication service name (you can name it as you like)OTEL_EXPORTER_OTLP_ENDPOINT- In this case, the IP of the machine where SigNoz is installed
IP of SigNoz backend is the IP of the machine where you installed SigNoz. If you have installed SigNoz on localhost, the endpoint will be http://localhost:4317 for gRPC exporter and http://localhost:4318 for HTTP exporter.
Paste this command in the terminal and your python application is again running on the port 5002.
OTEL_RESOURCE_ATTRIBUTES=service.name=sample-flask-application \
OTEL_EXPORTER_OTLP_ENDPOINT="http://localhost:4317" \
OTEL_EXPORTER_OTLP_PROTOCOL=grpc opentelemetry-instrument python3 app.py
But you haven’t seen anything in the SigNoz Cloud. There are two ways to send data to SigNoz Cloud. You can read that from here. In this guide, we are using the Send traces via OTel Collector binary, which is also recommended one as well.
OpenTelemetry-instrumented applications in a VM can send data to the otel-binary agent running in the same VM. The OTel agent can then be configured to send data to the SigNoz cloud. Refer to this documentation to download according to your platform and operating system.
Here are the steps to set up OpenTelemetry binary as an agent.
- After extracting otel-collector tar.gz to the
otelcol-contribfolder
cd otelcol-contrib
- Create
config.yamlin folderotelcol-contribwith the below content in it. ReplaceSIGNOZ_INGESTION_KEYwith what is provided by SigNoz andendpointaccording to your region :
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
cors:
allowed_origins:
- http://localhost:5002
hostmetrics:
collection_interval: 60s
scrapers:
cpu: {}
disk: {}
load: {}
filesystem: {}
memory: {}
network: {}
paging: {}
process:
mute_process_name_error: true
mute_process_exe_error: true
mute_process_io_error: true
processes: {}
prometheus:
config:
global:
scrape_interval: 60s
scrape_configs:
- job_name: otel-collector-binary
static_configs:
- targets:
# - localhost:8888
processors:
batch:
send_batch_size: 1000
timeout: 10s
# Ref: https://github.com/open-telemetry/opentelemetry-collector-contrib/blob/main/processor/resourcedetectionprocessor/README.md
resourcedetection:
detectors: [env, system] # Before system detector, include ec2 for AWS, gcp for GCP and azure for Azure.
# Using OTEL_RESOURCE_ATTRIBUTES envvar, env detector adds custom labels.
timeout: 2s
system:
hostname_sources: [os] # alternatively, use [dns,os] for setting FQDN as host.name and os as fallback
extensions:
health_check: {}
zpages: {}
exporters:
otlp:
endpoint: "ingest.{region}.signoz.cloud:443"
tls:
insecure: false
headers:
"signoz-ingestion-key": "<SIGNOZ_INGESTION_KEY>"
logging:
verbosity: normal
service:
telemetry:
metrics:
address: 0.0.0.0:8888
extensions: [health_check, zpages]
pipelines:
metrics:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
metrics/internal:
receivers: [prometheus, hostmetrics]
processors: [resourcedetection, batch]
exporters: [otlp]
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
logs:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
Depending on the choice of your region for the SigNoz cloud, the otlp endpoint will vary according to this table.
| Region | Endpoint |
|---|---|
| US | ingest.us.signoz.cloud:443 |
| IN | ingest.in.signoz.cloud:443 |
| EU | ingest.eu.signoz.cloud:443 |
- Once we are done with the above configurations, we can now run the collector service with the following command:
From the otelcol-contrib, run the following command:
./otelcol-contrib --config ./config.yaml
Step 4: Viewing Metrics and Traces of the Python application
After running the above application and making the correct configurations, you can navigate to the SigNoz services and traces to check that.
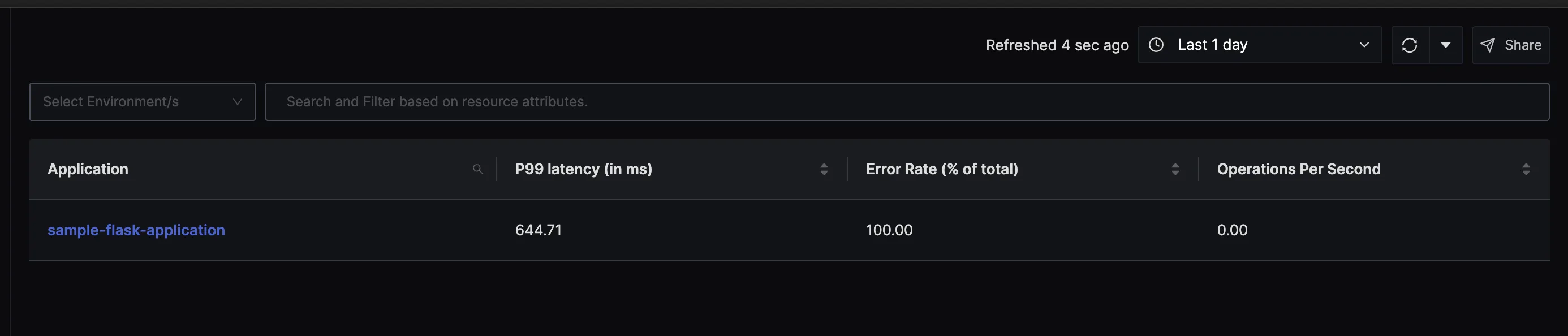
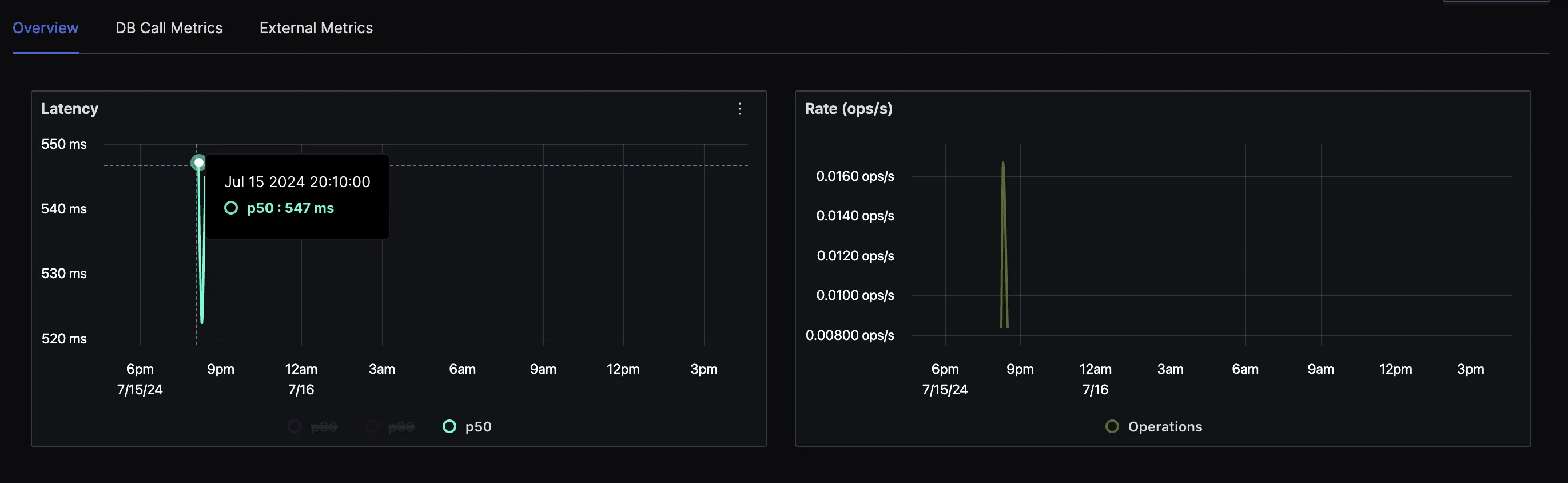
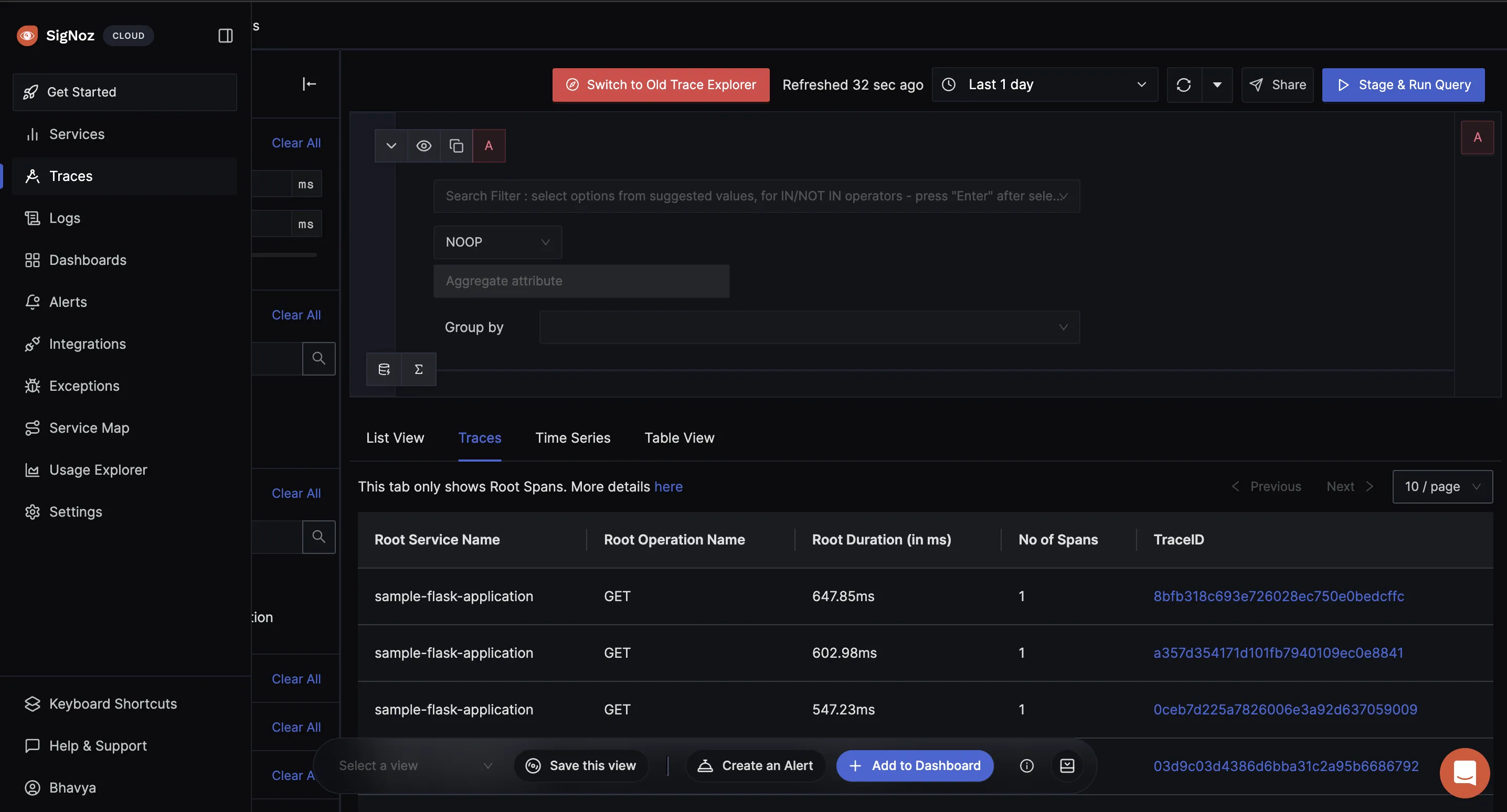
Best Practices for Implementing Python Performance Monitoring
To get the most out of your monitoring efforts:
- Choose the Right Instrumentation: Decide between automatic and manual instrumentation based on your application's complexity and your team's expertise.
- Implement Smart Sampling: Balance data granularity with performance overhead by using appropriate sampling strategies.
- Set Up Effective Alerts: Define meaningful thresholds and create clear escalation policies to address issues promptly.
- Create Insightful Dashboards: Design visualizations that provide at-a-glance understanding of your application's performance trends.
- Integrate with Development Workflow: Use monitoring data to inform code reviews and guide optimization efforts.
Monitoring with Python-specific Libraries
While comprehensive APM platforms offer broad monitoring capabilities, Python-specific libraries provide targeted performance analysis tools that can be invaluable for developers looking to optimize their code. Two notable examples are py-spy and memory_profiler:
py-spy
py-spy is a sampling profiler for Python programs. It lets you visualize what your Python program is spending time on without restarting the program or modifying the code in any way.
Key features:
- Low-overhead profiling
- Works with Python 2 and 3
- Doesn't require modifying your Python code
- Can profile Python programs that are already running
Example usage:
py-spy record -o profile.svg --pid 12345This command generates a flame graph of the running Python process with PID 12345.
memory_profiler
memory_profiler is a Python module for monitoring memory consumption of a process as well as line-by-line analysis of memory consumption for Python programs.
Key features:
- Line-by-line memory usage information
- Memory usage over time with mprof
- Works with Jupiter notebooks
Example usage:
from memory_profiler import profile @profile def my_func(): a = [1] * (10 ** 6) b = [2] * (2 * 10 ** 7) del b return a if __name__ == '__main__': my_func()Running this script with
python -m memory_profiler example.pywill output the memory usage for each line in themy_funcfunction.
These Python-specific tools complement broader APM solutions by providing deep, code-level insights that can be crucial for optimizing performance in Python applications. They're particularly useful during the development and debugging phases, allowing developers to identify memory leaks, excessive memory usage, and performance bottlenecks at a granular level.
Advanced Python Performance Optimization Techniques
To take your Python application's performance to the next level:
- Profile Your Code: Use tools like cProfile and line_profiler to identify specific lines or functions that are performance bottlenecks.
- Leverage Concurrency: Utilize asyncio, multiprocessing, or threading modules to improve performance in I/O-bound or CPU-bound operations.
- Implement Caching: Use Redis, Memcached, or in-memory caching to reduce database load and speed up repeated operations.
- Optimize Database Interactions: Fine-tune your ORM usage and write efficient SQL queries to minimize database-related performance issues.
Key Takeaways
- Monitoring Python applications in real time allows developers to identify and address the application's performance.
- With real-time insights, potential issues can be detected and resolved before they impact users and businesses, leading to a more reliable application.
- By tracking metrics like CPU and memory usage, developers can optimize resource allocation, leading to cost savings and better performance.
- Consistent monitoring helps maintain high performance, resulting in a better user experience and higher satisfaction.
- Monitoring provides valuable data that can inform decisions on scaling, updates, and optimizations, ensuring the application can handle real-world demands.
- With an observability tool like SigNoz, developers can continuously refine their applications, staying ahead of performance issues and enhancing overall quality.
FAQs
What's the difference between profiling and monitoring in Python?
Profiling involves detailed analysis of code execution, often in a development or testing environment. Monitoring, on the other hand, is an ongoing process in production environments, tracking high-level metrics to ensure overall application health.
How often should I review my Python application's performance metrics?
Review your metrics regularly — daily for critical applications, weekly for less crucial ones. Set up alerts for immediate notification of significant issues.
Can Python performance monitoring impact my application's performance?
While monitoring does introduce some overhead, modern tools are designed to minimize this impact. Proper configuration and sampling can help balance insight with performance.
What are some common pitfalls to avoid when implementing Python performance monitoring?
Avoid over-monitoring, which can lead to data overload. Focus on meaningful metrics, set realistic alert thresholds, and ensure your monitoring strategy aligns with your application's specific needs and goals.
How do you monitor the performance of Python?
You can use an observability tool like SigNoz for real-time monitoring and performance insights.
How to check the performance of Python code?
Employ profiling tools such as cProfile or Py-Spy to analyze the execution time and calls within your code.
Can Python be used for performance testing?
Yes, Python can perform performance testing using libraries such as Locust or PyTest-benchmark.
What is Python monitoring?
Python monitoring tracks application performance, errors, and system metrics to ensure optimal operation.
Is Python good for high-performance computing?
Python is versatile but not the fastest; however, it can be used effectively in HPC by integrating with faster backends like C or using PyPy.
How to create KPI in Python?
Define KPIs based on your application's critical metrics and use Python libraries like Pandas and NumPy to calculate and track these indicators.
How to improve Python code performance?
Optimize using efficient algorithms, reduce memory footprint, and employ just-in-time compilers like PyPy.
How do I check Python code optimization?
Benchmarking tools and profilers test various code versions and identify the most efficient implementation.

